 Management of Change (MOC) is a process for evaluating and controlling modifications to facility design, operation, organisation, or activities. It is one of the most essential elements of Process Safety Management (PSM). In the chemical process industries and Oil & Gas (CPI), MOC is required to ensure that safety, health and environment are controlled. Every year with monotonous regularity, major accidents related to MOC failure is significant and caused by lack of MOC management, resulting in thousands of lives being lost, and $ billions in lost production.
Management of Change (MOC) is a process for evaluating and controlling modifications to facility design, operation, organisation, or activities. It is one of the most essential elements of Process Safety Management (PSM). In the chemical process industries and Oil & Gas (CPI), MOC is required to ensure that safety, health and environment are controlled. Every year with monotonous regularity, major accidents related to MOC failure is significant and caused by lack of MOC management, resulting in thousands of lives being lost, and $ billions in lost production.
For the purpose of this article change is defined as the addition, modification or removal of anything that could influence it services. Change management is the process responsible for managing and controlling the lifecycle of all changes. To do this, change management supports the assessment, prioritization, authorization and scheduling of changes.
A Management of Change is crucial in any facility to ensure that:
- The change does not introduce new hazards to the facility or aggravate existing hazards, and potential hazards are adequately managed;
- The change does not disable / jeopardize any safety barriers in place; and
- Changes (even temporary ones) are adequately designed, assessed, approved by competent people and properly documented.
What are the common contents in an MOC procedure? While the MOC procedures vary among organizations, the following are minimum requirements in an MOC procedure (list is not exhaustive):
The Consequences of Mismanaging Change
Each of us has been a part of a change that was poorly managed, either as the offender or the victim. When projects and initiatives are mismanaged from the “people side of change” perspective, we don’t achieve the desired results and outcomes, in fact poor change management is responsible for many of the world’s worst disasters Including but not limited to the following
Flixborough (1974) – England: An explosion involving 30 tonnes of cyclohexane occurred at the caprolactam manufacturing plant. It had cost the lives of 28 workers, injured 89 others as well as extensive offsite damages. The explosion event was initiated from a temporary change. The plant personnel have decided to temporarily bypass a reactor which was leaking. Temporary piping was installed to bypass the faulty reactor and continue the process. However, the changes were done hastily with the following shortfalls, which led to the loss of integrity of the piping and subsequent release of cyclohexane and the explosion:
- No hazard/design review was undertaken
- Personnel designed and executed the change which were not professionally capable
- Poor documentation, design work and understanding of the changes and the hazards associated with it.
The Bhopal Toxic Gas Leak (India) Summary In December 1984, a toxic gas leaked from an Indian pesticide production plant after a maintenance worker failed to isolate sections of the plant whilst cleaning. The incident involved the release of Methyl Isocyanate resulting in deaths of thousands of people in the surrounding area of the plant. The disaster was initiated by a runaway reaction involving water leaking though a jumper line into Methyl Isocyanate storage Among other factors that led to the disaster, a poor management of change of installing the jumper line (having done no hazard assessments of the change) is one of the contributing factors.
This in conjunction with the failed defence of six safety systems, and numerous latent failures resulted in the poisonous gas escaping from the plant. The gas spread throughout the surrounding areas, which were mostly dominated by shanty housing, killing over 2000 people, and injuring a further 200,000.
Primary causes:
Failure of the maintenance worker to isolate the pipes whilst flushing them out allowed water to pass into a connected storage tank. The storage tank held vast quantities of the intermediate methyl isocyanate (MIC).
The influx of water caused an exothermic reaction, resulting in the temperature rising to over 200ºC and causing the pressure within the storage to rise. This resulted in the lifting of a relief valve on the storage tank, releasing the poisonous gas into the atmosphere.
Underlying causes
Prior to the gas release, operators identified the increased pressure of the tank. A MIC leak was also reported near the vent gas scrubber unit (VGS). Heat could also be felt radiating from the tank, and attempts were made to switch the VGS on, however this was inoperable. At the time of the incident the hazards associated with manufacturing highly toxic chemicals such as MIC were not fully understood.
This was evident in the finding that 10 times the required daily amount of the intermediate MIC was stored on site, as a matter of convenience, despite this being non-essential. items designed to prevent a MIC leak failed due to the systems being neglected by management, with the belief that the risks had decreased with the ceasing of production.
The prolonged period of inadequate and insufficient maintenance allowed the site to fall into a poor condition. During the early stages of the incident, operators also hesitated in using the warning siren system, eventually deploying the siren when the leak became more severe. There is still confusion as to the exact chemicals released into the atmosphere that day, partly due to the company’s reluctance to admit them.
Reaction and Going Forward Although Bhopal has been recognised as the worst recorded accident worldwide in terms of lives lost, the companies directly involved spent years debating blame and deferring compensation. Union Carbide India and eventually Union Carbide itself accepted a limited liability, however these companies were subsequently purchased by Dow Corning who have refused to accept liability for the disaster.
Bhopal may have come about as a result of an unplanned hazardous chemical release, but the seeds of this disaster were sown well before the event: Site selection –the site was in close proximity to a dense population center; – Bhopal may have provided cheap labour, however, the same pressures that reduced labour costs (excess of workers) also forced qualified individuals from the area to find work. As a result, Bhopal offered a limited pool of labour with a low skill set; staff were unsure how to respond to the accident; Technology – Union Carbide have subsequently been shown to have been using technology that was “untested and unproven” in their site in Bhopal; Reports that various warning signs were ignored, including concerns of inadequate safety measures.
Fail-safe equipment was either inadequate (water curtain) or inoperable (flame towers, gas scrubbers, emergency shutdown switch). Overall, it was the accumulation of factors that caused this incident. Each one of the points above may have caused smaller accidents but these points combined, resulted in a disaster of massive proportions. An overarching model of safety culture takes into consideration many of the issues raised above (senior staff attitude to safety/maintenance of safety equipment/job security)
King’s Cross Fire (Underground) Summary
In November 1987, 31 people were killed when a fire broke out at King’s Cross Underground station. The fire originated when an ignition source came into contact with flammable debris that had collected under the running tracks of the escalator.
Fifteen minutes later the ticket hall was evacuated, and the large metal gates closed. Approximately four minutes after this a flashover occurred engulfing the area in flames and intense heat.
Primary causes
The direct cause of the fire was probably a lighted match or cigarette, Which was dropped onto the running tracks of the escalator by a passenger.
Underlying causes
A smoking ban at the station, implemented in 1985, had resulted in passengers lighting up whilst on the escalators, as they prepared to leave the station. This had led to a number of smoldering’s’ (smaller fires which were assumed to be less of a threat) in the previous few years. Grease and dust had been allowed to accumulate on the escalator running tracks due to organisational changes that had resulted in poor housekeeping.
Along with the wooden escalators this provided the ideal seed bed for the fire to spread. The lack of any previous fires on escalators had encouraged a false sense of security amongst staff. This even extended up to higher management, and was reflected in the emergency procedures, even down to the use of the term ‘smoldering’s’ to classify such incidents. Inadequate fire and safety related training of the staff, in combination with a lack of smoke detectors beneath escalators, and staffs’ reluctance to call out the fire brigade all contributed to the perpetuation of the incidents seriousness.
Clapham Junction Rail Crash Summary
In December 1988, 35 people were killed, and hundreds more injured when a packed commuter train passed a defective signal, on route to Waterloo station. The train continued into the back of a second busy commuter train, causing it to veer off the tracks and into a third oncoming train. This incident did not result from the common unsafe acts and practices, such as wiring errors by the signalling technician, meant that the signal was incorrectly showing green
Primary cause
A new signalling system was being implemented, and following alterations to the Clapham Junction signal box, a signalling technician left two wires incorrectly connected to the same terminal of a relay.
The live wire was then able to make contact with the old circuit, which should not have contained any current, preventing the signal from turning to red, resulting in an incorrect green signal and causing the system to fail.
Underlying cause
There were a number of underlying causes that contributed to this incident. Most predominantly was the lack of monitoring and supervision, which according to the official report ‘did not confine itself to immediate superiors’. This was compounded by the lack of training, despite the need being recognised, up to three years preceding the incident. Sloppy work practices were blamed for the loose wires that were left in place. This had evolved into an established work method for saving time, despite similar wiring errors being made a couple of years previously. The signalling technician responsible for the wiring oversight had worked for 12 hours on the day of the accident, with only a five-minute break in that time. It is recognised there were no effective systems for monitoring or restricting excessive working hours.
Southall Rail Crash Summary
In 1997, seven people died and 150 were injured when a Great Western train, on route to Paddington collided with a freight train
Primary causes
The primary cause of the incident was the driver’s inattention, which allowed the train to pass through two signals that should have warned the driver of the impending obstacle, the freight train blocking the track up ahead.
Underlying causes
The initial driver error was compounded by faulty safety equipment. The Great Western train had both the basic ‘Automatic Warning System’ (AWS) and a second more advanced pilot version ‘Automatic Train Protection’ (ATP) installed. The AWS was broken at the time of the incident and the driver was not trained in the use of ATP, rendering both systems ineffective.
AIR: Challenger space shuttle disaster Summary
In late January 1986, NASA flight 51-L was destroyed in a total loss explosion just following take off. Failure of the O-ring seal had resulted in the release of a stream of ignited fuel, which caused the shuttle to explode.
Primary causes
The immediate cause of the eventual explosion was a split, which developed shortly after the launch, in the O-ring seals between the lower two segments of the shuttle’s starboard solid rocket booster (SRB). This allowed fuel to leak, eventually igniting.
Underlying causes
Safety, Reliability and Quality Assurance staff failed to collect essential safety data. They, therefore, neglected to identify the trend in O-ring failures, experienced by more than half of the fifteen missions preceding Challenger the shuttle’s SRB manufacturer had expressed concern as to the circumstances in which they were deployed
The specification rendered them unsafe to operate at temperatures below 53º Fahrenheit, as is the case during takeoff. The SRB was not tested in an accurate, launch authentic situation.
Constraints on resources meant that spare parts were kept in short supply, whilst pressure was put on staff to achieve unrealistic launch schedules. This also resulted in the 71% reduction of safety and quality control staff prior to the disaster. The evolution of a culture where a certain level of risk was expected, even so far as to be deemed ‘accepted’ meant that such deviances were normalized, and as a result, numerous warning opportunity were missed prior to the disaster.
Reaction and Going Forward
The Rogers commission was formed to report on the major causes of the Challenger accident. Interestingly, the organisational safety culture at NASA came under serious criticism with commission members citing this as a major accident antecedent. Examples of poor safety culture ranged from inadequate risk identification and management procedures through to an organisational structure that did not allow for the individual concerns of independent contractors to be heard.
NASA embarked on a radical overhaul of their safety assessment procedures with the explicit goal of raising standards. A safety committee was established and allocated independent status concerning launch/no launch decisions. The Challenger disaster also provided academics with concrete proof concerning the impact that a defective safety culture can have upon a high-risk environment. The accumulation of unresolved issues concerning safety allowed human factors specialists such as James Reason to suggest a Swiss Cheese model of accident causation, and, more importantly, allowed researchers to point at possible methods of behaviorally addressing safety culture issues. NASA was accused of failing to learn the lessons of the past after the Columbia disaster in 2003.
Columbia space shuttle disaster Summary
During the re-entry sequence, an American shuttle experienced a breach of its Thermal Protection System (TPS). This breach allowed superheated air to penetrate the insulation, melting and weakening the aluminum structure. The aerodynamic forces in operation, ultimately, caused a total loss of control. All seven crew members died as a result of the disintegration of the shuttle
Primary causes
Shortly after the launch of the shuttle a section of insulating foam separated from the bipod ramp of the external left tank. This struck the left wing as it fell, causing the eventual TPS breach. Despite engineers’ suspicions, only minor investigations were carried out, neglecting to identify the missing foam or the impact damage.
Underlying causes
The inadequate design of the Bipod ramps was fundamental to this particular incident. Little consideration was given to the aerodynamic loadings the ramps were exposed to during launch, and the use of foam, which is not considered a structural material, only contributed to the unsuitability. Additionally, a level of complacency had evolved following previous failure of the ramps, which had resulted in no serious damage.
The complacency had resulted in a confidence based on past success, instead of a focus on sound engineering practices. The official report also uncovered other ‘cultural traits and organizational practices detrimental to safety’ that were allowed to develop.
The shuttle flight schedule was considered unrealistic and put excessive pressure on planned launches to go ahead. The deadlines were not regularly re-evaluated to ensure their continuing viability. Organizational barriers to effective communication of safety critical information were identified by the official incident report, along with ‘stifled professional differences of opinion’ and a lack of integrated management across the various program elements.
Reaction and Going Forward
As mentioned previously, NASA has faced considerable criticism concerning a perceived failure to react to the issues raised in the Challenger investigation. The Columbia investigation board again cited safety culture as causal and made recommendations intended to address these issues going forward. Since the Columbia disaster NASA has followed more explicit rules governing launch/no launch decisions resulting in a serious reduction in the number of missions scheduled and completed. An emphasis has now been placed upon a new design of reusable aircraft that can be designed from the ground up with safety in mind.
Kegworth Air Crash Summary
In January 1989, 47 people were killed when a Boeing 737, on its return flight from Heathrow to Belfast, experienced engine vibration and smoke. The crew acted to stabilize the situation until an emergency landing could be performed, however the measures taken failed and the passenger craft hit the ground, coming to a final standstill on the westerly embankment of the M1, Motorway at Kegworth.
Primary causes
The initial smoke and vibration experienced by the crew was the result of a fan fracturing in the No. 1 engine. Using their knowledge of the aircraft, its air conditioning system and instrumentation the order was mistakenly given to throttle back (shut down) the No. 2 engine. Unfortunately, this action coincided with a reduction in engine vibration, confirming an erroneous belief. This resulted in the loss of power (i.e. the good engine), and sole reliance on the damaged engine.
Underlying causes
The crew failed to assimilate the readings on the engine instrument display prior to throttling the No. 2 engine. The official incident report states that the crew therefore ‘reacted to the initial engine problem prematurely and in a way that was contrary to their training.
The reduction in noise and vibration that coincided with the throttling of the No. 2 engine persuaded the crew that the defective engine had been correctly identified.
Meanwhile, the flight crews’ workload remained high throughout the subsequent landing preparations, preventing follow up appraisals of the situation. The poorly designed layout of engine instrument displays had previously been accepted, however recent adjustments had resulted in the instruments now using LED displays for engine indications. No additional alerting system was fitted to identify the defective engine to the pilots. Passengers and cabin crew also failed to question the commander’s announcement or bring the discrepancy, which referred to the ‘right’ engine despite them witnessing smoke from the left engine, to the attention of the crew.
Reaction and Going Forward
The extensive Air Accident Investigation Branch (AAIB) report that followed Kegworth outlined technical and human factor failures that lead to and worsened the disaster.
Recommendations were varied, from correct brace position training (taken up by industry) through to reverse facing seating (not taken up for passenger comfort reasons). The most telling recommendation, however, concerned the passage of information throughout the cabin. As witnessed in other air accidents it was recognised that the authority of the Commander should not come at the expense of common sense. Many passengers and crew correctly identified the burning engine but failed to raise this when the other unit was shut down.
Everyone is susceptible to error, even the most experienced Commanders. It was recommended that flight deck culture should allow for error to be addressed in a secure environment with the aim of improving standards and therefore safety levels.
COAL MINING Aberfan Coal Waste Tip Slide Summary
In 1966, 144 people (mostly children) were killed when a portion of a coal waste tip slid down the mountainside, in South Wales. The tip collapsed onto the small mining village, crushing a local school.
Primary causes
It was well known by locals that the tip had been located on an underground spring, as well as on a sloping mountainside. In addition, two days of heavy rain preceding the incident had loosened the slag piles, resulting in the eventual tip slide.
Underlying causes
Visibility was at approximately 50 yards due to mountain fog. Although the tipping gang on the mountainside saw the tip begin to slide, many people down in the village saw nothing. The lack of an adequate warning system also contributed to the resultant devastation. Inspections were not carried out routinely, and the company also failed to employ adequately competent people. forty years previously a similar incident had taken place elsewhere.
Despite the causes having been investigated and published, the information was not applied to Aberfan, and the incident was allowed to repeat. However, it is also worth noting that such literature was not as widely available as other mining-related literature due to a perceived distinction between the hazards associated with mining as opposed to the ‘peripheral’ issue of tips.
The Tribunal of Inquiry identified a ‘pervasive institutional set of attitudes, beliefs and perceptions’, which resulted in a collective neglect of safety regarding the tip by numerous regulatory and governing bodies.
The National Coal Board also failed to take responsibility for the tip slide by denying all knowledge of the underground spring situated beneath the tip. The official enquiry revealed this was not the case, Employee involvement, learning, culture, attitude toward blame. Uses data/ recommendations from accident enquiries as well as academic and applied research.
Focused on effective safety culture, how to create and maintain safety culture and the characteristics of both positive and negative safety cultures from cross-industry research. e.g. A blame culture is characterized by staff trying to conceal errors, employees feeling fearful and reporting high stress levels. Employees are not recognised or rewarded thus lacking motivation and errors are ignored or hidden.
Details of each indicator are included in the report and the summary of each point is copied here:
Sinking of the ‘Herald of Free Enterprise’ (1987) – violation by the Crewmember responsible for ensuring closure of the bow doors, poorly organized shifts inadequate staffing; inadequate emphasis on safety from management; pressure to sail early; ‘negative reporting’ policy.
Piper alpha (1988) – inadequate communication between shifts regarding Maintenance work systems; modification to the design of the platform without adequate risk assessment and planning,
Grounding of the ‘Exxon Valdez’ (1989) inadequate communication between the captain and the third mate, and inadequate safety culture (prevalence for excessive drinking of alcohol among crew). Nuclear incidents: More recently, there have been significant incidents reported in the nuclear industry, but they were recognised sufficiently early prevent their escalation to a major accident. (2005) here I briefly discuss two such incidents in a paper on the organisational contributions to nuclear power plant safety. Some of the issues highlighted were:
Davis Besse Nuclear Power Station Incident (2002) – severe vessel head corrosion resulting from inadequate processes for assessing safety of the plant; delayed shut down of the plant; failure to recognize and consider other secondary warning signals in a holistic fashion; inadequate safety culture meant this issue was never identified or dealt with; failure to reflect latest practices within industry; inconsistent and incomplete company policies on safety; incentive programs based on production levels not safety.
Paks Fuel Damage Incident (2003) – fuel damage resulted from inadequate new procedures i.e. the unsafe design and operation of the cooling system; inadequate reporting culture; inefficient monitoring systems; no alarm; inadequate organisational commitment to safety; inadequate sharing of safety information. Findings from research papers Work by the University of Liverpool (1996) analyzed publicly available investigation reports for the contribution of attitudinal and management factors.
They found the main underlying causes of accidents in the chemical industry included: maintenance errors, inadequate procedures, inadequate job planning, inadequate risk assessments, inadequate training of staff, unsafe working condoned by supervisors/ managers, inadequate control and monitoring of staff by managers, inadequate control and monitoring of contractors working on site, etc.
Pomfret et al (2001) looked at safety behaviour linked to accidents and near misses in the offshore industry They investigated the underlying structure and content of offshore employees’ attitudes to safety, feelings of safety and satisfaction with safety measures. Their results suggest that ‘unsafe’ behaviour is the ‘best’ predictor of accidents & Incidents /near misses as measured by self-report data and that unsafe behaviour is, in turn, driven by perceptions of pressure for production. Those employees, who had reported performing unsafe acts and violations, and those who felt that they were under more pressure to keep production going, were more likely to have been involved in one or more near miss on that installation in the past two years.
Pomfret (2005) examined a number of incidents from the nuclear, offshore, gas and chemical industries, to determine contributing factors which, had they been picked up by inspection and/or assessment, may have prevented an incident. The underlying causes for most of the incidents reviewed were; maintenance procedures; operating procedures; assessing competence; plant inspection; plant and process design; risk assessment; and management of change These causes were similar across the major hazard industries.
Work by the Vectra Group Ltd. (2004) planned to identify the ways in which human factors ‘best practice’ may be integrated into an offshore maintenance strategy. They noted that incidents resulting from maintenance are more likely to stem from a human factors-related root cause than engineering ones (60% of all incidents were identified as human factors related).
In our research to develop human factors methods and associated standards for major hazard industries, Pomfret, et al (2003) analyzed accident case studies and identified five human factors topics that were influencing accidents in the chemical industry. Those topics were: procedures, availability of information, communications, emergency planning, and accident investigation. In (2005) we investigated the organisational contribution to nuclear power plant safety and discussed the findings of the investigations into Davis Besse Nuclear Power Station Incident (2002) and Paks Fuel Damage Incident (2003). They also reported on two other studies to look at the underlying causes of accidents in nuclear power plants. The first of these reports by the United States Nuclear Regulatory Commission (US NRC) analyzed 48 events at US nuclear power plants for human performance contributions and found human errors were included among the root causes in 37 of the events.
The second study was by the Organisation for Economic Co-operation and Development’s (OECD) Nuclear Energy Agency (NEA) (2003) on recurring events in the nuclear industry. Management and organisational factors that were revealed as root causes in multiple events, and specific behaviour included: deficiencies in safety culture in general; deficiencies in communication; deficiencies in work practices such as not following procedures, lack of clear work responsibilities, improper use of system diagrams; a lack of design basis information available; inadequate management; heavy workload; and insensitivity to shutdown risk activities “The implicit assumption is that safety culture is clearly a pervasive and important aspect of operations but one whose effect on risk may be difficult to quantify.
The Bomel Consortium (2003) conducted a comprehensive review of the factors and causes contributing to major accidents, across all industry sectors, between 1996/97 and 2000/01. The key issues of concern were identified at three levels in the organisation. At the individual level, ‘competence’ (linked to ‘training’), ‘situational awareness and risk perception’ (linked to ‘communications’ and ‘availability of information and advice’), and ‘compliance’ were highlighted as being linked to accidents.
At the organisational level, ‘management and supervision’, ‘planning’, and ‘safety culture’ issues were highlighted and ‘safety management’ at the corporate Policy level. Part of the work included an analysis of the results by industry sector for details relating to each sector). The industry sectors included in the analysis were, Agriculture and Wood, Construction, Engineering and Utilities, Food and Entertainment, metals and Minerals, Services, Polymers and Fibres, and Hazardous Installations (including, onshore and offshore oil companies, mining, and chemical processing plants). It is noted in the report that, there is surprising consistency in the dominant failings uncovered across the sectors and across different accident kinds, process environments and employment
Petroleum refinery just outside of downtown Philadelphia, PA
More recently there was another story in the news about a major chemical accident in the United States. On June 21, 2019 a major explosion at injured five workers and endangered thousands of nearby Philadelphia residents. The damage was so severe that the facility was ultimately forced to close its doors and lay off hundreds of its employees, and the full health and environmental impact of the accident has still not been determined.
The sad fact is that major chemical-related accidents like these are far more common than you’d think. A 2016 EPA review of chemical incidents found that over 2,200 chemical-related accidents had occurred between 2004 and 2013, killing 59 people and injuring over 17,000. That’s an average of about 150 fires, explosions and other hazardous releases each year.
Evidence of poor safety culture include: lack of ownership; isolationism; lack of learning; unwillingness to share safety information or co-operate; failure to deal with the findings of independent external safety reviews; often due to a lack of management commitment. Strengths Good overview of key papers, research papers and accident enquiries. Focused on learning from major accidents as well as research.
Prepared with a view to applying the knowledge Provides evidence of the characteristics regarding positive and negative, the types of behaviour associated with each, and to a limited extent, how change management.
Change Management
Change management is an enabling process, so beneficial changes can be made to systems and services, with minimum disruption to them. The scope of change management includes Process Safety, IT applications, networks, servers, desktops, laptops, tools, architectures, processes, organizational structures and operating instructions. Changes to any of these should be managed using a consistent change-management approach and must include:
- Ensuring the change is recorded somewhere
- Assessing the change for risk to existing services
- Approving the change if needed
- Checking the success or lack of success of the change
- Reviewing the positives and negatives of the change-management process, so improvements can be made
The roles in change management
It is important to understand the different roles in change management. For some types of managed changes, the same person may be in these roles. Teams may also be in these roles, as all team members share the responsibility for the change-management task. The three main roles in change management are:
Change authority
The change authority is an important figure in change management. This is the person or persons who are responsible for granting approval for the change. In a good implementation of change management, this responsibility will vary depending on the type of change, the details of the change, the risk of the change failing, the impact of any failure and the system to which the change is being applied.
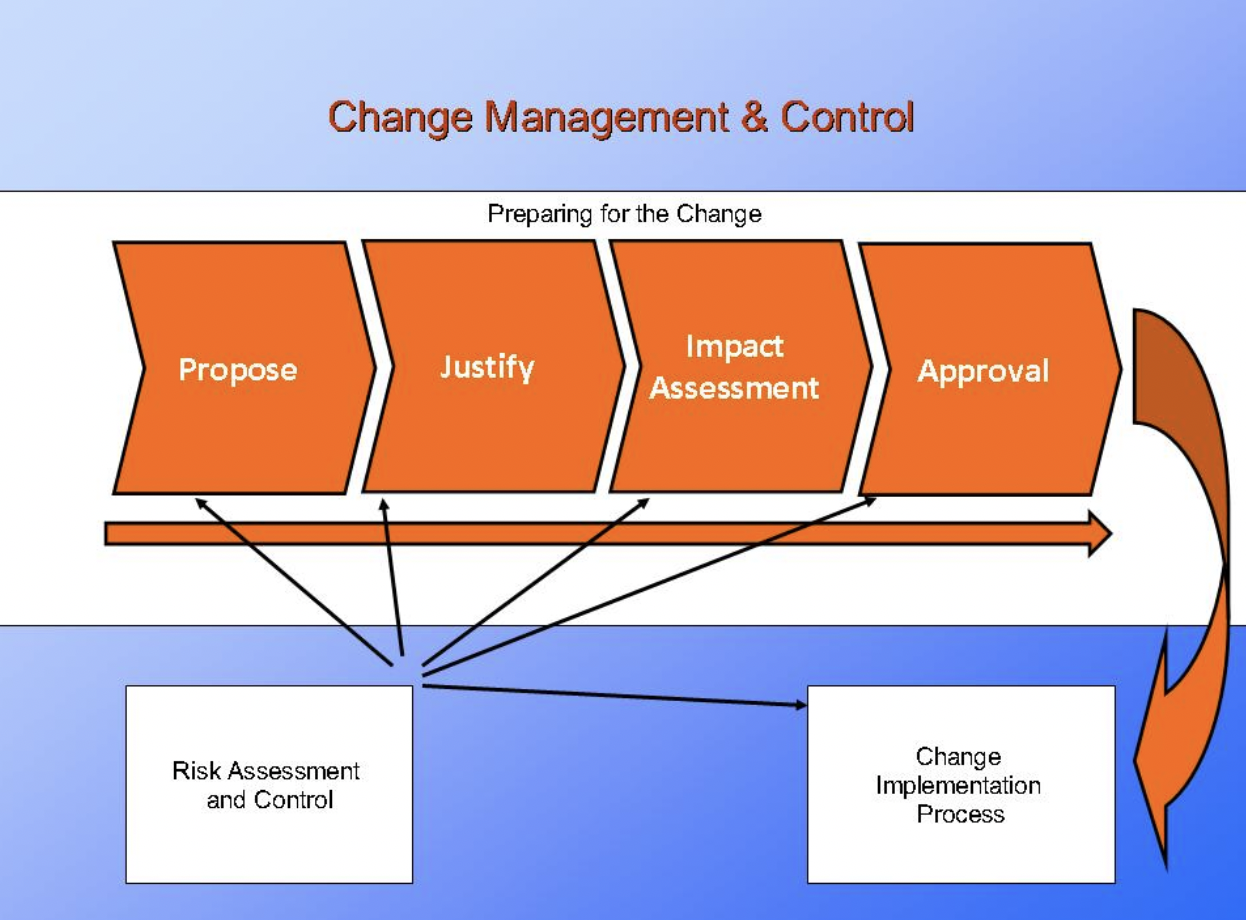
There will be several different change authorities, which should be defined in a change management policy and procedure. Examples of change authorities are a change-advisory board (CAB), a change manager and an IT support technician. The concept of change authorities helps to share the responsibility for approving changes among more people than just the “change manager.” Using different change authorities will avoid delays in implementing changes and help to manage any overloads in the change-management process.
Change owner
The change owner is the person who wants the change to happen. The change owner is accountable for the success of the change, even when someone else is managing the change or is responsible for its implementation. The change owner is responsible for requesting the change, often using a standard form known as a request-for-change (RFC). When the change owner is not also the change authority. as defined in the change-management policy or procedure, the change owner is responsible for presenting the RFC to the appropriate change authority for approval.
This could involve representing the change at a change meeting. The change owner is often the product owner, with responsibility for that service, especially when the change is made and managed is to the service functionality or architecture.
Change reviewer
Others, but not all, may need to review changes before they can be approved. The conditions under which changes require independent review will be defined in the change-management policy. Some changes are low risk and repeatable, but not all of them fall into this category. If a PC is plugged into a network socket, then that’s a change, but you wouldn’t expect the engineer to initiate a formal Request-For-Change and have someone else review it before the engineer completed this simple task. If a change was submitted with a considerable amount of new functionality, however, then it’s a good idea for the service-desk manager to review the change to ensure his or her staff is aware of the new functionality and when it will be deployed.
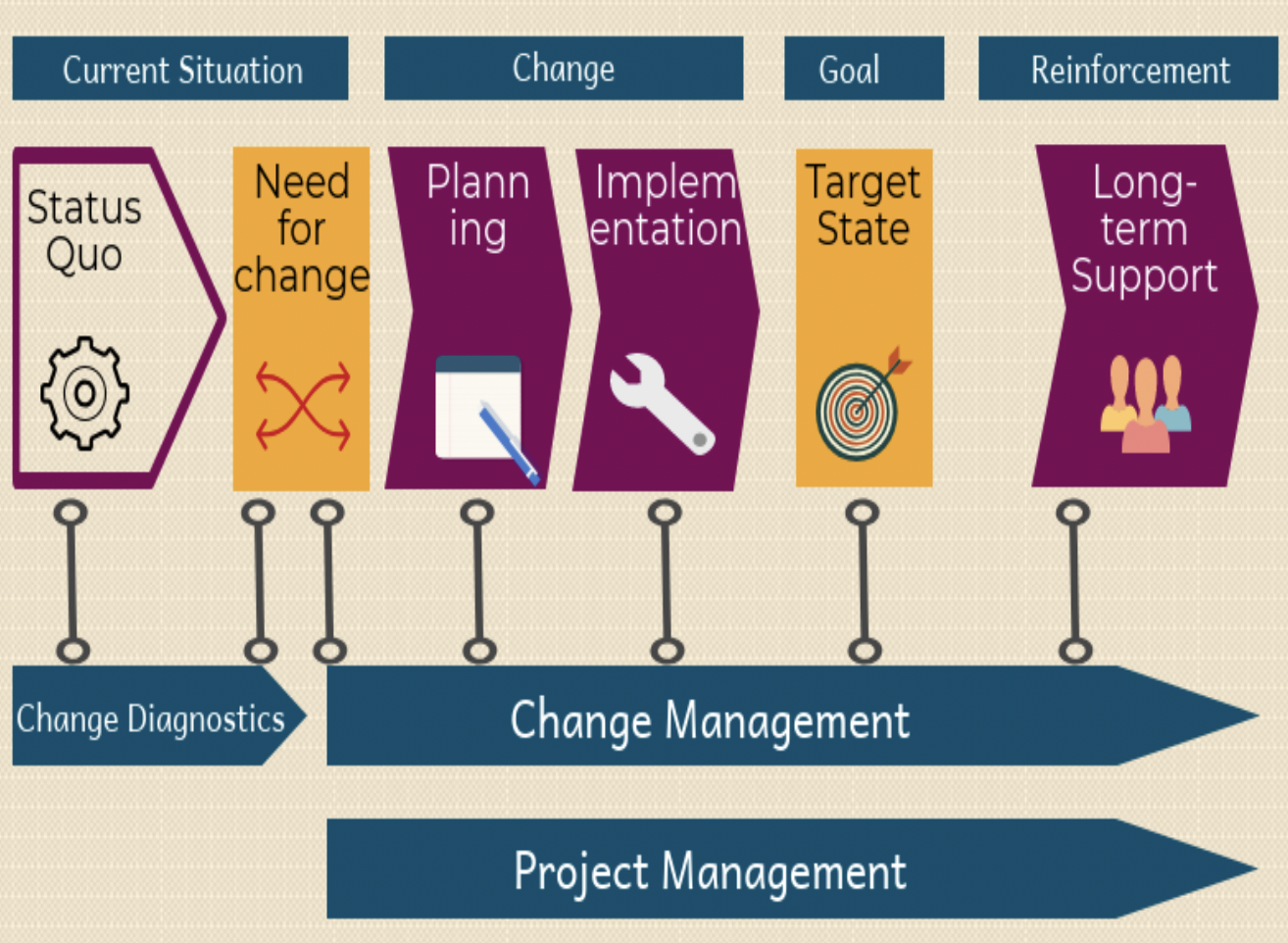
What are the different types of change in change management?
There are three different types of change in best-practice change management: emergency changes, standard changes and normal changes. It is important to understand their differences.
Emergency change
An emergency change requires urgent approval that cannot wait for the normal cycle of the change-management process. An emergency change, therefore, is a change that must be managed and applied to resolve or prevent a high-severity incident, where the fix is urgent and the impact to the business of not applying the change is very large. In good change management, changes must not be defined as emergencies just because someone forgot to submit the change to change management for approval within the agreed time period.
It is normal practice to have a separate variant of the change-management process to manage emergency changes. Emergency change-management processes typically have specific requirements for approvals and recording the change that supports the urgent management of the change. The change authority for managing emergency changes is often the major incident manager, who may agree all the change-management paperwork can be completed after implementation of the emergency change.
Standard change
A standard change is both low risk and repeatable. It has been successfully managed and executed many times. Examples include managing the connection of a PC to a network, applying routine malware updates and minor software patches. There should be a variant of the change-management process that defines how standard changes are treated. The change-management policy should include the definition of what is a standard change for an organization and how the changes are to be managed. The manager responsible for change management should maintain a complete list of the agreed-upon standard changes.
The management activities for the execution of every standard change should be recorded, but there is no requirement to initiate an RFC for them in the change-management process. In the management of standard changes, the change owner is often also the change authority, meaning the change can be executed without additional approvals from others in the change-management process.
The use of standard changes is a good method to stop the change manager and not being overloaded with many low-risk changes.
Normal change
A normal change requires management but is not a standard or an emergency change. There should be a variant of the change-management process to manage normal changes. An organization will typically create a normal change as its first change-management process, which is then used as the basis to create the management processes for emergency changes and standard changes. In a normal change-management process, the change owner submits an RFC to the team responsible for change management a minimum number of days before a planned implementation date. This allows the person or team responsible for change management enough time for an initial assessment of the change, and then, if necessary, distributed to stakeholders and ITSM specialists for review. The change and the review comments are then presented to the change authority for approval. This could be at a meeting of a CAB or the change manager might approve it. The change-management policy should define the change authorities for normal changes. Normal changes should be included on a schedule of changes showing all changes being managed.

The principles of best-practice change management are? Change management is a process, but unless everyone is focused on its important principles, there is considerable risk change management will add overhead, but provide no value to an organization’s business outcomes.
Change management as an enabler: Without focusing on the principles of change management, it can be perceived as an obstacle to making desired changes. Change management must be able to process changes at the pace the business requires. To assist in maintaining this pace, change-management practitioners should be proactively engaged in the development lifecycle, offering advice and guidance to ensure the change can progress through the change management process without any delays. Proactive engagement will also help the people involved in the change management process to understand the contents of a change, avoiding unnecessary questions at any approval stage, which can delay the deployment of changes.
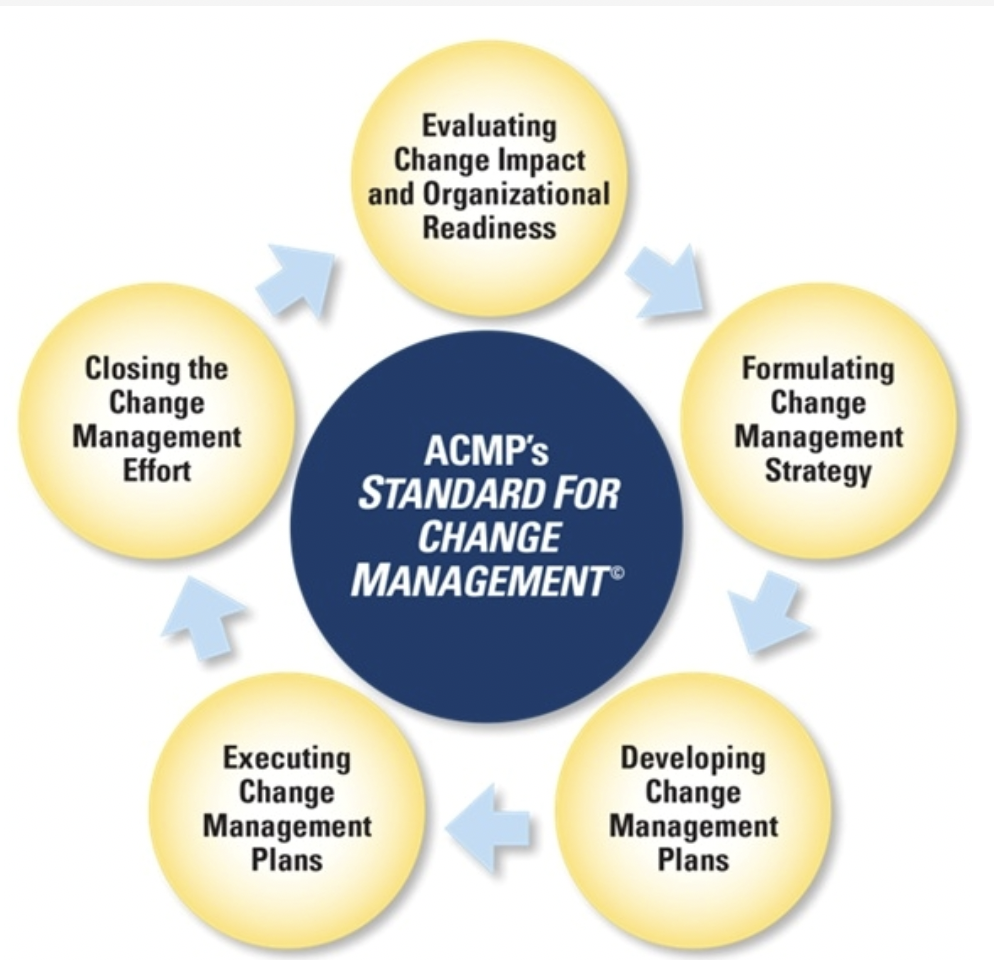
Following this principle will help to ensure the change-management process adds value to an organization and does not become just a “box-ticking” exercise. Change management is not an agreement of the change requirements with users, or building, testing or deploying the change. These are the responsibility of the related release-management process, not change management. Good change management, however, can help to ensure changes work as intended by checking those responsible for each phase have approved their part. This should include confirmation of the testing of the change and its deployment method, the completion of any necessary training and the change owner is satisfied the change is ready to be deployed.
No blame culture, with collective responsibility
In best-practice change management, no one should be blamed if a change fails. Change management should ensure a failed change is investigated, so lessons can be learned in advance of the next change, but without assigning blame. The individual or team responsible for change management should have good working relationships with the many people and teams who are part of the lifecycle of a change, from inception to actual use. Everyone involved in the end-to-end workflow of managing the change must act as if he or she is a member of the same team with the same goal. To avoid blame in change management, all those involved in the lifecycle of a change should take collective responsibility to ensure the change works, and with a shared goal to satisfy the customer.
Large proportion of standard changes approved without a CAB
Achieving a large proportion of standard changes compared to the total number of changes is a change-management goal. These standard changes will be recorded, approved and executed without any involvement from a CAB. Achieving this principle is a good indicator of mature change management, as it demonstrates trust between IT and ITSM, and a culture that focuses on the purpose of change management and not just following a change-management process.
What are the activities of a change-management process?
Change management includes several activities and sub-processes. It is important these are considered for every type of change. Noting the detail and execution effort for each of these change-management activities will vary according to the type of change and its characteristics.
For example, for a standard change, the change-management activities for RFC creation, review, change evaluation, assessment, approval and closure are all completed at the same time, often by the change owner.
Create and record RFC
The change owner creates an RFC and records it in the location defined in the change-management policy procedure. An RFC provides the information required to manage the change, including a description, required date and the name of the change owner. The change-management policy may require additional information for normal and emergency changes, including assessments of risk and impact and back-out plans.
Review RFC
Some change-management policies require an initial assessment of an RFC for a normal change to verify all required information has been provided. If any information is missing, then an RFC can be rejected and returned to the change owner.
Assess change
Depending on the outcome of the evaluation, an RFC may need to be circulated to the reviewers identified in the change-management policy, so they can conduct their assessment of the change. When the change manager is the change authority, as defined in the change management policy, then he or she can conduct the assessment.
Approve change
The change authority defined in the change-management policy will either approve or reject the change after considering the outcomes of any assessments, any clashes with other changes and the information presented in an RFC. The approval or rejection should always be recorded in the location, according to the change-management policy.
Review and close RFC
Many RFCs are closed as soon as a change has been implemented. If a change fails, then before an RFC can be closed, a review should be conducted to identify any required improvements. This can include recommending amendments to the change-management process or the change-management policy.
Who should approve changes in best-practice change management?
In best-practice change management, there will be several change authorities who are authorized to approve certain types and classes of change. The approvers should be defined in the change-management policy and can include the change owner, the person executing the change, local management, the change manager, the CAB and the executive board of the organization. For standard changes, the change-management policy normally defines the change authority as the change owner or the person executing the change. For emergency changes, the approver is usually the major-incident manager who is responsible for the incident requiring the change. Local management often approves changes where the scope of the change is limited to just one part of IT, with no risk of affecting users.
This approach can be usefully employed in DevOps environments, where the product owner or the scrum master acts as the change authority, in effect, acting as a change manager. The CAB should be involved in change-management approvals only if a change has a large impact or high risk; requires a service outage; or is complex, requiring the involvement of multiple teams. Final approval may be required from an organization’s executive board for very high-risk and very large-impact changes that could significantly and adversely impact the day-to-day business of the organization.
Improving the efficiency of the CAB in change management
Without careful design, CABs can be one of the most inefficient parts of the change-management process, and for several reasons:
- Ensuring the change is recorded somewhere
- Assessing the change for risk to existing services
- Approving the change if needed
- Checking the success or lack of success of the change
- Reviewing the positives and negatives of the change-management process, so improvements can be made
Technology can address these issues by deploying techniques to create a “virtual CAB,” improving the efficiency of the CAB and the overall change-management process. Workflow tools can automatically route RFCs on receipt to the appropriate reviewers.
Collaboration tools, including social media and Web-conferencing platforms, can enable change discussions to occur before a CAB meeting. These tools can even be used to conduct the CAB, with no need for everyone to be in the same physical space. Technology enables virtual CAB meetings to be called on demand, including to manage emergency changes and support attendance by people in any location.
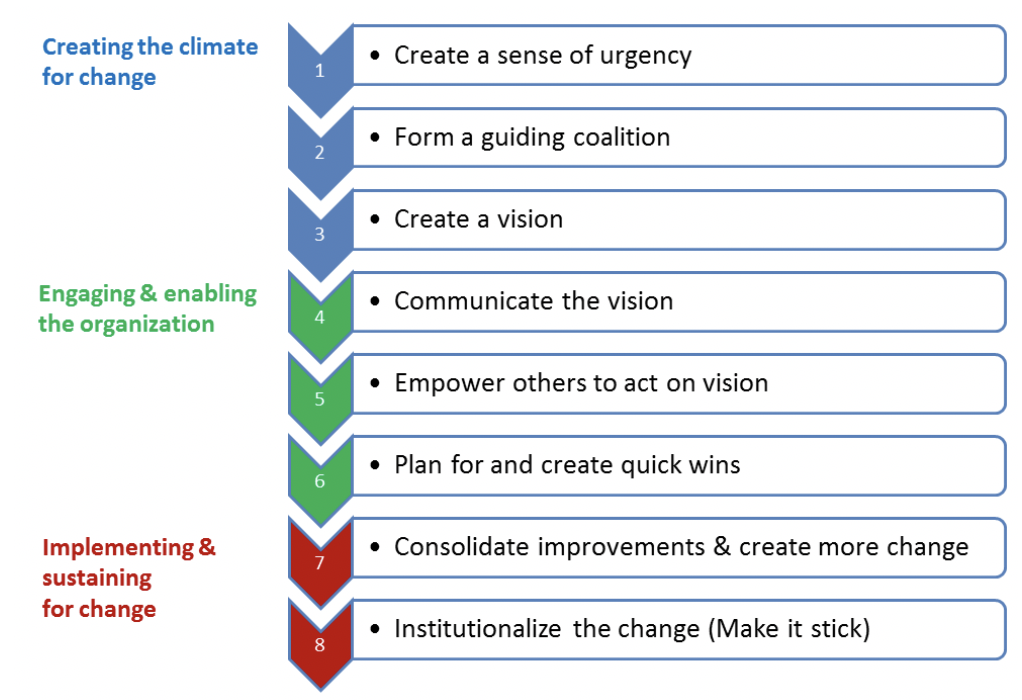
Managing major changes
In a major change, many configuration items must be introduced or changed at the same time, for example, a major application upgrade that needs a hardware expansion and significant user training or a change with a very high risk or very large impact to the users of the services. An example of the latter is when the implementation of the change requires management of an extended outage during working hours. The steps to approve a major major change often requires more attention and approval from a higher level of an organization. A major change, therefore, must be considered much earlier in the change-management process, and more information is required than is requested in an RFC. A change proposal can be used for the initial stages of a major change. This change proposal is an early communication about the change, so the risk, impact and feasibility can be assessed before any significant investment made.
How can you receive approval to implement change management?
The first step to obtaining approval to implement change management is to gather some data and evidence about the impact of not having an effective change management process. These can be obtained from users, IT and the service desk. Analyze all the service outages and disruption during the last 2 or more years that occurred after a change had been made. If you can’t obtain any historical evidence, then start collecting it from today. Most organizations without change management will have experienced at least one high-impact failure following the release of a change. Once the evidence has been gathered, estimate the cost of the impact on the business and IT. This can be calculated according to the number of minutes lost and the average cost of a worker.
Add the cost of the time IT spent recovering from the failures when it could have been working on improvement projects. Lost business may be another cost factor, for example, customers who visited other online systems.
The costs of implementing change management can then be justified by contrasting them with the total loss incurred due to failed changes.
How can you best implement change management?
The first step to implementing change management is to understand fully how changes are currently managed, so you can keep what works well and make informed decisions on areas of priority. This is achieved by identifying a baseline and consulting with everyone involved in the lifecycle of managing changes. Once the baseline has been established, discuss the expected outcomes from implementing change management and reach an agreement with stakeholders of the business, IT, development.
This will help senior management to maintain focus on why change management is being implemented within the organization. Once an agreement on outcomes has been reached, the activities to support the necessary changes in attitude, behavior and culture (ABC) should start and continue throughout and beyond the change-management implementation.
There are then two options to implement change management: a phased approach or “big bang.”
The choice of option will depend on the baseline position for change management, the resources available for implementation, the rate of changes currently being managed and an organization’s appetite for risk.
Phased approach
In this approach to implement change management, a small start is made and lessons are learned, and then the scope is expanded. The initial scope of change management can be according to service, for example, introducing the new change-management approach for all changes to a service; by the type of change, such as major changes first; or by IT function, such as application changes. A phased approach for change management can require more time to complete, but if you start with a small scope, then you can test your change-management approach and adjust easier. According to other companies’ experiences, a phased approach is usually more successful.
Good change management starts with the first step. Organizations are advised to make a start, however small. A good approach is to start a phased approach by selecting an area where change management can make a visible and positive difference. It is highly likely some mistakes will be made, which is normal when introducing a process or policy as complex and all-encompassing as change management. It is important to learn from your mistakes and be prepared to adjust your change-management process, policies, training and education.
Good change management starts with the first step. Organizations are advised to make a start, however small. A good approach is to start a phased approach by selecting an area where change management can make a visible and positive difference. It is highly likely some mistakes will be made, which is normal when introducing a process or policy as complex and all-encompassing as change management. It is important to learn from your mistakes and be prepared to adjust your change-management process, policies, training and education.
Dr Bill Pomfret; MSc; FIOSH; RSP. FRSH;
Founder & President.
Safety Projects International Inc, &
Dr. Bill Pomfret & Associates.
26 Drysdale Street, Kanata, Ontario.K2K 3L3.
www.spi5star.com pomfretb@spi5star.com
Tel 613-2549233